Image similarity search tutorial
Topics covered:
- 1vN similarity search by uploading image
- 1vN similarity search by choosing an image from your data set
- NvN similarity search
- Similarity search history
- Similarity search via REST api
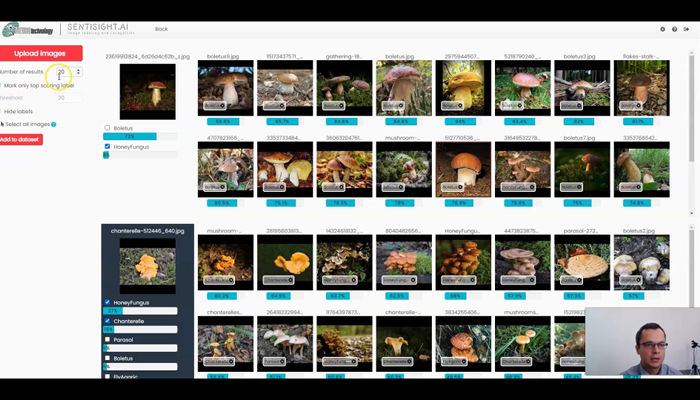
Labeling by image similarity tutorial
Topics covered:
- Labeling by image similarity feature
- Changing parameters
- Adjusting suggested labels manually
- Performing AI-assisted labeling iteratively
- Downloading classification labels
