
Machine Learning Solutions
Image recognition and annotation platform
Computer vision consultancy and custom projects
Explore
The endless possibilities available to your organization via SentiSight.ai's Image Recognition Site & Platform
Our specialist expertise within the field of image recognition can be utilised in a variety of different forms, tailored around your business requirements to deliver a solution that helps you achieve your goal.

Image Annotation Tools
Speed up the image annotation process with our customizable range of AI-powered image annotation tools.
Machine Learning Platform
Train your own image recognition models using our online platform that is easy to use yet powerful for experts.
![]()
Custom Projects
We can help you build a bespoke image recognition solution tailored to the requirements of your business.

Consulting
Our computer vision consulting is designed to help you de-risk the adoption of AI into your business practices.
Computer Vision models you can deploy on SentiSight.ai

Object Detection
Build an image recognition model that can locate objects within images using our Object Detection Model Builder Tool.

Image Classification
Use the Image Classification Model Builder Tool to build and train image recognition models to predict the content of images.

Image Similarity Search
Use our Image Similarity Tool to find visually similar images within your data set.

Pre-trained Models
Get started with turnkey AI solutions available to integrate into your project without the need for coding or training.
The turnkey solution for
Your Image Recognition Online Projects

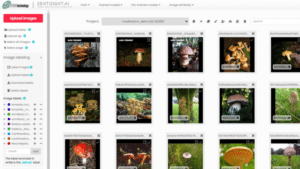
Label images
Most image recognition projects require labeling the content of images, but this has often been a long and labor intensive process. Using our image recognition site's online platform, users benefit from a customisable range of AI-assisted image annotation tools to speed up this image labeling process.
Once labeled, the images can either be used on the SentiSight.ai platform or downloaded for offline use.

Build and Train
After choosing the right image recognition model for your project, use the SentiSight.ai online dashboard to build and train your own model. Beginners to image recognition can simply build their own models, whilst experts are able to customise the training parameters to create detailed and powerful models.
If you have an idea in mind, then our image recognition site is the place to build it!

Deploy your Model
Once built, SentiSight.ai offers a range of useful ways to use your model for your image recognition projects. Users have the choice to use the image recognition models online using the SentiSight.ai online dashboard, via REST API or even downloaded for offline use.






